ComoRAG
综合介绍
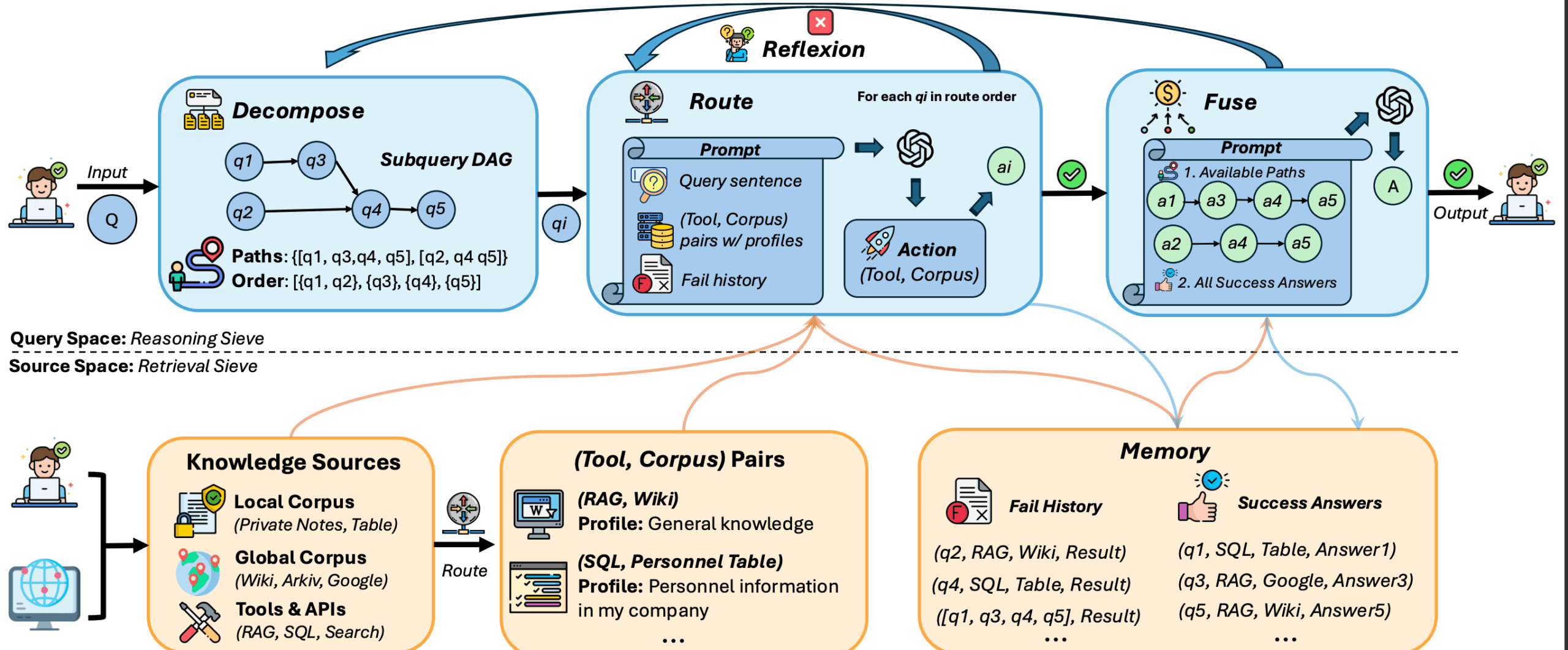
ComoRAG 是一个开源的检索增强生成(RAG)系统,专为处理长文档和多文档任务设计。它支持问答、信息提取和知识图谱构建,整合了大语言模型(LLM)、嵌入模型、图增强推理和多种评估工具。系统灵感来源于人类认知的记忆机制,通过迭代推理、动态探查和全局记忆池,解决复杂长篇叙事理解问题。ComoRAG 在超长上下文(20万+ token)基准测试中表现优异,相比传统 RAG 系统提升高达11%,特别适合需要全局理解的复杂查询。它的模块化设计便于扩展,适用于学术研究和实际应用。
功能列表
- 支持多种大语言模型和本地/远程嵌入模型,灵活适配不同需求。
- 提供图增强检索与推理,优化长文档信息整合。
- 灵活的数据预处理与分块,支持按词、句或递归分块。
- 内置多种评估指标,如 F1 分数、精确匹配(EM),用于结果验证。
- 模块化架构,易于扩展和自定义,适合研究与生产环境。
使用帮助
安装流程
ComoRAG 的安装简单,适合 Python 3.10 或以上版本。以下是详细步骤:
- 安装依赖下载项目后,进入项目根目录,运行以下命令安装依赖:
pip install -r requirements.txt
依赖包括支持大语言模型和嵌入模型的库,推荐使用 GPU(支持 CUDA 12.x)以提升性能。
- 设置环境变量
- 如果使用 OpenAI API,需设置 API 密钥。
- 如果使用本地 vLLM 服务器,需指定模型路径和服务器地址。
- 示例环境变量设置:
export OPENAI_API_KEY="your-openai-api-key" export VLLM_MODEL_PATH="/path/to/your/model"
- 准备硬件GPU 非必须,但推荐使用以加速推理。确保 CUDA 12.x 已安装。
数据准备
ComoRAG 需要两种数据文件:
- 语料库文件(corpus.jsonl):每行是一个文档,包含
id、doc_id、title和contents字段。示例:{"id": 0, "doc_id": 1, "title": "文档标题", "contents": "文档内容"} - 问答文件(qas.jsonl):每行是一个问题,包含
id、question和golden_answers字段。示例:{"id": "1", "question": "问题内容", "golden_answers": ["答案1"]}
快速开始
ComoRAG 提供两种运行方式:使用 OpenAI API 或本地 vLLM 服务器。
方法 1:使用 OpenAI API
- 修改
main_openai.py中的配置:config = BaseConfig( llm_base_url='https://api.example.com/v1', llm_name='gpt-4o-mini', dataset='cinderella', embedding_model_name='/path/to/your/embedding/model', embedding_batch_size=32, need_cluster=True, output_dir='result/cinderella', save_dir='outputs/cinderella', max_meta_loop_max_iterations=5, is_mc=False, max_tokens_ver=2000, max_tokens_sem=2000, max_tokens_epi=2000 ) - 运行程序:
python main_openai.py
方法 2:使用本地 vLLM 服务器
- 启动 vLLM 服务器:
vllm serve /path/to/your/model \ --tensor-parallel-size 1 \ --max-model-len 4096 \ --gpu-memory-utilization 0.95或使用 Python 启动:
python -m vllm.entrypoints.openai.api_server \ --model /path/to/your/model \ --served-model-name your-model-name \ --tensor-parallel-size 1 \ --max-model-len 32768 \ --dtype auto - 修改
main_vllm.py中的配置:vllm_base_url = 'http://localhost:8000/v1' served_model_name = '/path/to/your/model' config = BaseConfig( llm_base_url=vllm_base_url, llm_name=served_model_name, llm_api_key="your-api-key-here", dataset='cinderella', embedding_model_name='/path/to/your/embedding/model', embedding_batch_size=4, need_cluster=True, output_dir='result/cinderella_vllm', save_dir='outputs/cinderella_vllm', max_meta_loop_max_iterations=5, is_mc=False, max_tokens_ver=2000, max_tokens_sem=2000, max_tokens_epi=2000 ) - 运行程序:
python main_vllm.py - 检查服务器状态:
netstat -tlnp | grep 8000 curl http://localhost:8000/v1/models
数据处理与评估
- 文档分块使用
chunk_doc_corpus.py对文档进行分块:python script/chunk_doc_corpus.py \ --input_path dataset/cinderella/corpus.jsonl \ --output_path dataset/cinderella/corpus_chunked.jsonl \ --chunk_by token \ --chunk_size 512 \ --tokenizer_name_or_path /path/to/your/tokenizer支持的分块方式包括按词、句或递归分块。
- 问答评估使用
eval_qa.py评估问答结果:python script/eval_qa.py result/cinderella输出结果包括
details和results.json,支持 F1、EM 等指标。
核心功能操作
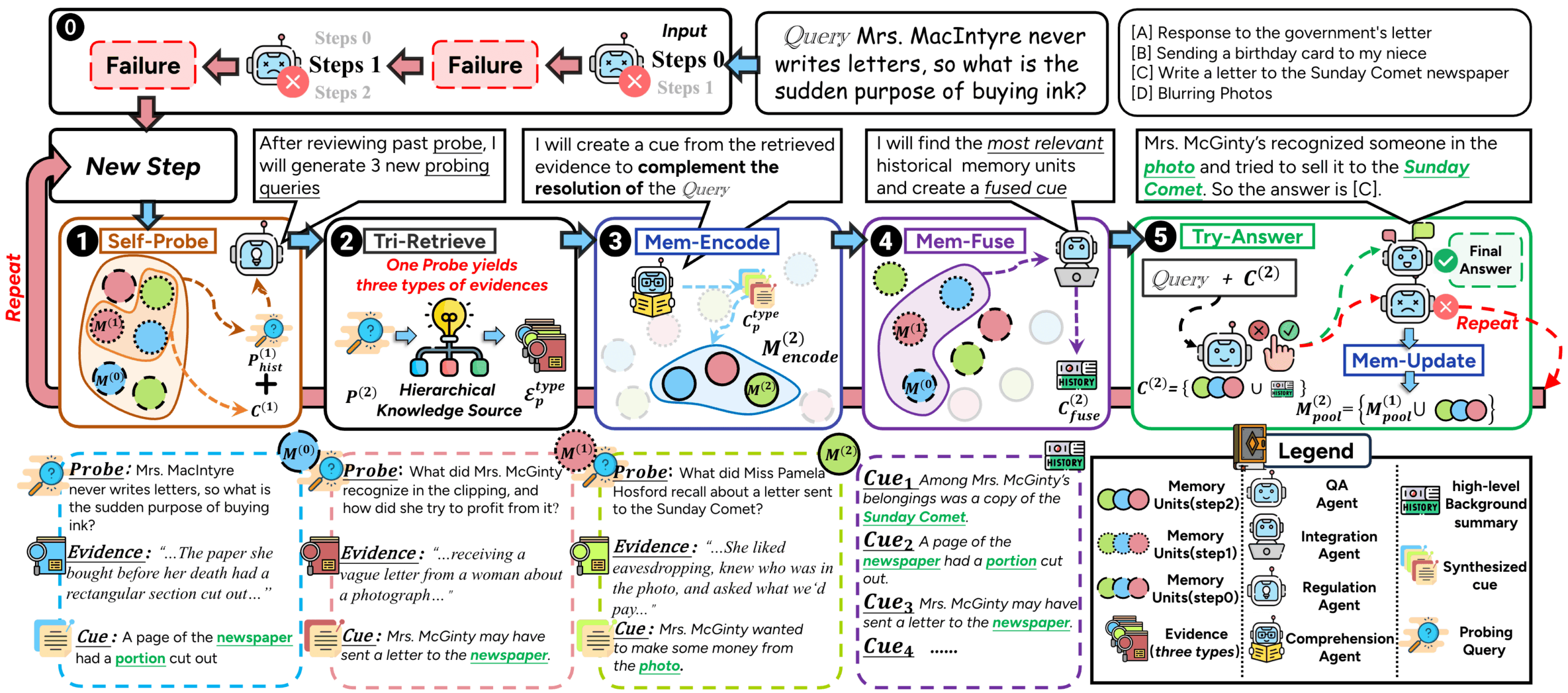
- 迭代推理循环:ComoRAG 通过“推理-探查-检索-整合-解决”循环处理复杂查询。用户可通过设置
max_meta_loop_max_iterations控制循环次数。 - 图增强检索:系统构建知识图谱,整合多文档信息,提升长上下文理解能力。用户可通过
need_cluster=True启用语义和情节增强。 - 全局记忆池:新检索的信息会整合到记忆池中,逐步构建查询的完整上下文。用户可在
save_dir查看记忆池输出。 - 灵活模型支持:支持多种大语言模型和嵌入模型,用户可通过配置文件指定模型路径或 API。
注意事项
- 确保数据格式正确,字段缺失可能导致运行错误。
- 本地 vLLM 服务器需要足够 GPU 内存,推荐至少 16GB。
- 结果保存在
result/<dataset>/<subset>/目录,建议定期清理以节省空间。
应用场景
- 学术研究ComoRAG 适合分析长篇学术文献,提取关键信息或构建知识图谱。研究人员可输入多篇论文,生成结构化知识,快速回答复杂问题。
- 小说分析对于长篇小说,ComoRAG 可处理复杂情节和人物关系,回答全局性问题,如“某角色在故事中的动机是什么”。
- 企业文档管理企业可使用 ComoRAG 处理大量内部文档,提取信息或回答跨文档查询,如合同条款分析或技术文档检索。
- 法律文件处理律师可利用 ComoRAG 分析多份法律文件,快速定位相关条款或构建案件知识图谱。
QA
- ComoRAG 支持哪些模型?支持多种大语言模型(如 GPT-4o-mini)和嵌入模型,可通过 OpenAI API 或本地 vLLM 服务器运行。
- 如何处理超长文档?系统通过分块和图增强检索,将长文档分解为小块,结合全局记忆池整合信息,确保高效处理。
- 本地运行需要 GPU 吗?GPU 非必需,但推荐使用以加速推理。至少需要 CUDA 12.x 和 16GB 显存。
- 如何评估问答效果?使用
eval_qa.py脚本,支持 F1、EM 等指标,结果保存在指定输出目录。